Computer Vision Algorithms
Python, Numpy | 2019
As part of Brown's Computer Vision course, I had become much more comfortable using Python and Numpy to perform operations on 2D images. Many of these projects included feature recognition/matching and image classification while providing a practical introduction into deep learning using CNN's. Here are some of the projects below:
Local Feature Matching
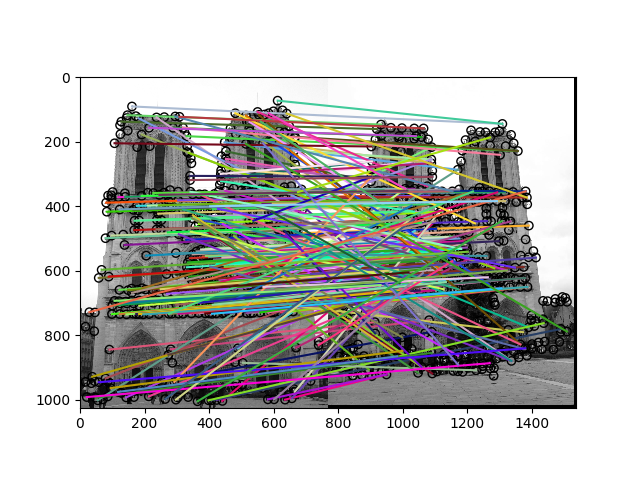
Given multiple views of the same scene, I wrote an algorithm that uses SIFT keypoint detection to identify and recognize clear points of interest that can be matched between photos. I began generating "interest points" by calculating the 1st and 2nd degree derivatives along each dimension using sobel convolution. By calculating the 2nd moment matrix with appropriate filtering and thresholding, I could generate key points of interest.
Once these points were identified, I then used a 16x16 image patch to generate a histogram bin of features based on each subpatch's gradient. After key features were identified and classified, I could then match features using a nearest neighbor calculation based on the built histograms.
Once these points were identified, I then used a 16x16 image patch to generate a histogram bin of features based on each subpatch's gradient. After key features were identified and classified, I could then match features using a nearest neighbor calculation based on the built histograms.
Image Classification
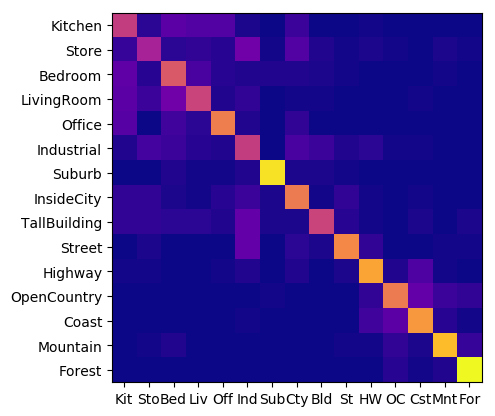
In order to classify a set of images, I had written several different approaches to scene recognition
The first approach was to generate "tiny image" representations of the inputs to represent its identifying features.
The second approach was to build an identifying vocabulary (or "bag of words") based on the training image's histogram of gradients and to cluster the identifying data points using K-Means.
With both of these methods of generating image features, I could then classify testing images against training images and labels using nearest neighbor calculations based on the euclidean distance between feature points.
The final approach was then taking the same "bag of words" from the second method, but instead using a SVM linear classifier to fit training data and predict results during testing. I found this method to be the most effective and also the most straightforward function to write. While there definitely is so much more for me to learn about deep learning, I have been pleasantly surprised by its usability and I am very excited to delve deeper and implement more of it into my workflow.
** while I can't post the code itself due to academic code reasons, I'd be very happy to provide it upon request **
The first approach was to generate "tiny image" representations of the inputs to represent its identifying features.
The second approach was to build an identifying vocabulary (or "bag of words") based on the training image's histogram of gradients and to cluster the identifying data points using K-Means.
With both of these methods of generating image features, I could then classify testing images against training images and labels using nearest neighbor calculations based on the euclidean distance between feature points.
The final approach was then taking the same "bag of words" from the second method, but instead using a SVM linear classifier to fit training data and predict results during testing. I found this method to be the most effective and also the most straightforward function to write. While there definitely is so much more for me to learn about deep learning, I have been pleasantly surprised by its usability and I am very excited to delve deeper and implement more of it into my workflow.
** while I can't post the code itself due to academic code reasons, I'd be very happy to provide it upon request **